
Les concepts les plus importants qui façonnent le domaine des grands modèles de langage (LLM) ont d’abord été présentés sous forme d’articles de recherche, avant de se diffuser dans l’industrie et auprès du grand public.
Ces publications proviennent aussi bien de la recherche académique traditionnelle, que des travaux de grandes entreprises : OpenAI, Anthropic, Mistral…
Elles sont la meilleure source d’information dont on puisse rêver pour comprendre les évolutions récentes de l’intelligence artificielle. Mais les articles de recherche sont longs et ne sont pas conçus pour être pédagogiques.
C’est là que nous intervenons en tant qu’organisme de formation dans le domaine de l’IA ! Voici notre résumé de 5 publications essentielles pour comprendre l’essor de l’IA générative et des LLM.
Le titre de la célèbre publication qui a introduit le tout aussi célèbre modèle GPT-3 est surprenant : “Language models are few-shot learners”.
En français, cela signifie que les modèles de langages apprennent sur la base de quelques exemples, que l’on peut inclure dans le “prompt”.
L’apport mis en avant dans cet article n’est donc pas tellement la capacité de GPT-3 à parler comme un humain, mais plutôt sa capacité à traiter des tâches qui auparavant nécessitaient des algorithmes spécialisés.
GPT-3 est peu l’équivalent du premier smartphone : au lieu d’avoir un modèle par tâche à accomplir, comme analyser le sentiment d’une phrase, identifier des noms propres ou traduire un texte, on peut soudainement utiliser un seul grand modèle de langage pour tout faire.
Il reste nécessaire de donner quelques exemples au LLM pour obtenir de bons résultats, c’est la notion de “few-shot learning”. Vous trouverez aussi parfois le terme “in-context learning”.
L’intérêt d’un LLM est que l’on peut fournir les exemples en même temps que l’on pose sa question. Auparavant, il aurait fallu a minima spécialiser un modèle existant en le réentraînant (“fine-tuning”), voire créer un nouvel algorithme à partir de zéro.
Cette approche donne naturellement naissance à la discipline du “prompt engineering”. Tout le monde peut obtenir de bons résultats avec un LLM sur des tâches complexes, à condition d’apprendre à lui parler comme il faut.
On parlait déjà d’IA, de machine learning et de deep learning avant l’arrivée des LLM. Pourtant ceux-ci semblent avoir provoqué une véritable rupture dans la recherche comme dans l’industrie. Pourquoi ?
Le premier L de LLM, c’est pour “Large”. Tout simplement car leur capacité de généralisation découle d’un effet de taille, en nombre de neurones si l’on fait l’analogie avec le cerveau humain. C’est ce que le papier “Scaling Laws for Neural Language Models” démontre.
Les lois de passage à l’échelle permettent de prédire l’incrément de la précision d’un modèle en fonction de sa taille, du volume de données mobilisé pour l’entraînement et de la puissance de calcul consommée. Elles indiquent que l’architecture de réseaux de neurones profonds “Transformer” passe extrêmement bien à l’échelle, ce qui justifie donc d’investir dans l’entraînement de très très grands modèles.
D’ailleurs, plus le modèle est grand, mieux il utilise les données à sa disposition, ce qui conduit les chercheurs à conclure : “big models may be more important than big data.”.
Les modèles massifs seraient plus importants que les données massives. Il n’empêche que les LLM restent entraînés sur des jeux de données gigantesques !
Vous entendrez parfois le terme de “modèle de fondation” comme synonyme de LLM, mais aussi dans d’autres contexte que le traitement du langage naturel : la génération d’image, de vidéos… en fait dans tous les domaines où le deep learning existe.
Un modèle de fondation est un modèle conçu pour être générique, typiquement via un entraînement sur un panel de données vaste et hétérogène. On peut l’utiliser directement, ou le spécialiser à la marge sur un jeu de données plus spécifique (fine-tuning).
L’article “On the opportunities and risks of foundation models” trace une différence entre l’apprentissage profond (deep learning) et les modèles de fondation qui en sont une évolution plus récente.
Les chercheurs utilisent deux critères :

Une histoire résumée de l’IA, qui va vers toujours plus d’homogénéisation, avec des modèles qui deviennent naturellement capable de comprendre un phénomène, d’analyser les caractéristiques des données, voire de fournir des fonctionnalités clé en main.
“Transformer”, prononcé à l’américaine “transformeur”, n’est pas un type de robot géant qui cherche à détruire le monde, mais le nom de l’architecture de réseaux de neurones profonds sous-jacente aux modèles larges existants aujourd’hui.
Cette architecture est relativement simple, au sens où elle use et abuse d’un seul mécanisme : les couches d’attention. Le titre de la publication qui a introduit les Transformer s’appelle donc sobrement “Attention is all you need”.
Comme l’a démontré l’article d’OpenAI sur les “scaling laws”, elle passe particulièrement bien à grande échelle, c’est pourquoi elle est à ce jour à la base de l’essentiel des modèles de fondation.
Même si elle peut traiter n’importe quel type de séquence, il s’agit plutôt d’une architecture conçue pour le traitement du langage naturel, où les séquences sont donc des suites de mots : les questions que l’on pose à son LLM préféré par exemple, et la réponse que l’on obtient.
On voit émerger des variantes spécialisées pour d’autres types de données comme les séries temporelles, mais qui restent dans la famille des Transformers.
Les papiers cités jusqu’à présent nous ont appris que :
Le revers de la médaille est que l’entraînement d’un LLM ou d’un modèle de fondation au sens large est très coûteux, sur la plan économique et aussi écologique. On ne peut pas refaire les fondations de sa maison chaque semaine !
Si l’on veut qu’un LLM continue à suivre l’actualité, il va falloir lui fournir des informations fraîches directement dans le prompt. Pour un développeur voulant générer un programme, il peut s’agir de fournir la documentation la plus récente montrant la syntaxe à jour d’une librairie de code.
La “Retrieval-Assisted Generation” ou “RAG” automatise cette tâche. Il n’y a pas vraiment de publication ayant créé la notion de “RAG”, qui est étudiée depuis longtemps et s’est fortement développée avec l’arrivée des LLM. Vous pourrez donc retrouver une revue de littérature récente dans les références en bas de page, qui décrit en profondeur la notion de RAG.
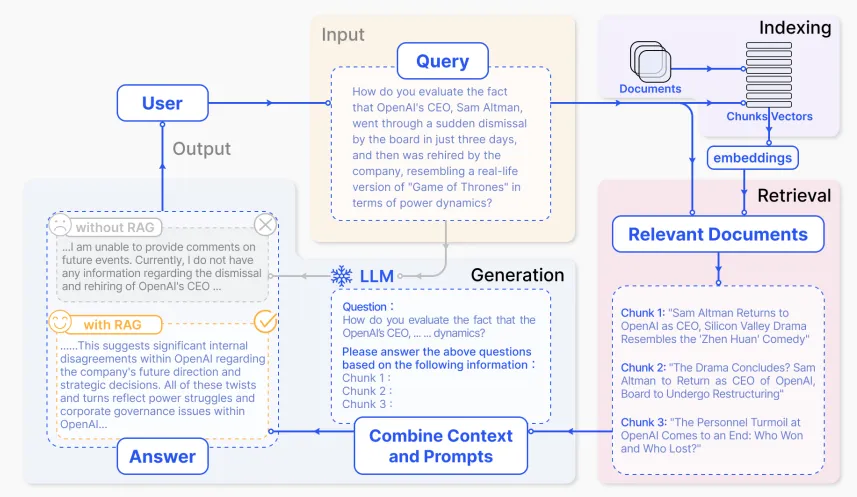
Définition précise d’un RAG par Gao et al. (2023) : l’utilisateur entre une requête, le système récupère des documents pertinents pour cette requête, le LLM génère sa réponse, qu’on espère meilleure avec ce nouveau contexte que sans !
En général, les RAG utilisent lors de l’étape de retrieval un sous-produit des LLM, les “embeddings” ou plongements en bon français. On parle aussi de vectorisation ou encore de recherche sémantique. Cela leur permet de faire des recherches à partir de phrases entières et en tenant compte des synonymes, ce qu’une recherche “classique” aura du mal à faire.
Pour l’implémentation, on ne peut que recommander le framework open source LangChain. On l’apprécie tellement, que l’on a ouvert une formation en une journée pour construire un RAG avec LangChain !
Il y a une telle quantité de publications de recherche sur les LLM et les modèles de fondation qui émergent chaque semaine qu’il est irréaliste de vouloir se tenir à jour en temps réel, sauf si vous êtes un chercheur expert du domaine.
Les documentations techniques des acteurs de l’IA, des LLM et du cloud computing sont de bonnes bases pour aller plus loin sans se perdre. AWS et IBM produisent par exemple de bons articles de définition de concepts. Tout comme bien sûr les différents producteurs de LLM comme OpenAI, Anthropic ou en France, notre champion Mistral.
Par exemple, vous pouvez explorer par vous même le terme “agent”, qui n’est pas si facile à définir et joue pourtant un rôle majeur dans l’utilisation efficace de l’IA générative.
Et surtout, il faut pratiquer ! Si vous avez aimé cet article, vous apprécieriez probablement nos formations à l’IA en entreprise et à LangChain, qui vous donnerons toutes les clés pour mobiliser l’IA générative dans votre métier.
Merci pour votre lecture !
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., … & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901. https://arxiv.org/abs/2005.14165
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., … & Amodei, D. (2020). Scaling laws for neural language models. arXiv preprint arXiv
.08361. https://arxiv.org/pdf/2001.08361Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., … & Liang, P. (2021). On the opportunities and risks of foundation models. arXiv preprint arXiv
.07258. https://arxiv.org/abs/2108.07258Vaswani, A. (2017). Attention is all you need. Advances in Neural Information Processing Systems. https://user.phil.hhu.de/~cwurm/wp-content/uploads/2020/01/7181-attention-is-all-you-need.pdf
Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., … & Wang, H. (2023). Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv
.10997. https://arxiv.org/pdf/2312.10997Vous avez apprécié cette ressource ?
Découvrez toutes nos formations Next.js, Astro.js et LangChain en présentiel ou en distanciel