Les LLM ont provoqué une petite révolution en démocratisant l’utilisation de l’intelligence artificielle, avec qui l’on peut désormais tenir des conversations.
L’IA est est au cœur de toutes les discussions, dans le monde professionnel et en dehors. Mais d’abord, qu’est-ce que l’IA ? Et qu’est-ce qu’un LLM ? Parle-t-on tous bien de la même chose ?
Ces nouvelles technologies viennent avec un vocabulaire étendu et qui ne cesse de s’enrichir et qui peut être difficile à cerner.
Voici un lexique complet pour vous aider à voir plus clair.
Tout d’abord, avant de parler des LLM, commençons par rappeler le principe de l’intelligence artificielle.
- Intelligence artificielle : domaine scientifique visant à reproduire l’intelligence humaine, notamment afin d’automatiser des tâches complexes. Les LLM et l’IA générative étant très populaires, on entend parfois parler d’IA pour désigner spécifiquement ces technologies, mais l’intelligence artificielle est une discipline beaucoup plus vaste.
- Machine learning : apprentissage automatique. Il s’agit d’apprendre à un programme à résoudre une tâche, à partir d’un protocole d’entraînement, par exemple en lui montrant de nombreux exemples. Quand on parle d’intelligence artificielle, il s’agit souvent d’apprentissage automatique, mais il existe d’autres formes d’intelligence artificielle comme les systèmes experts ou la logique floue.
- Modèle : le terme modèle désigne un algorithme qui utilise des techniques de statistiques pour mettre en œuvre l’apprentissage automatique. On appelle modèle l’algorithme en lui-même, par exemple “la régression linéaire” est un modèle. Mais on appelle aussi modèle une instance de l’algorithme entraînée sur des données particulière, par exemple “un modèle qui prédit les ventes de glaces à la fraise en fonction de la température extérieure”.
 Les modèles de machine learning peuvent être entraînés pour réaliser des tâches diverses et variées, par exemple prédire un volume de vente (on parle aussi de “forecasting”).
Les modèles de machine learning peuvent être entraînés pour réaliser des tâches diverses et variées, par exemple prédire un volume de vente (on parle aussi de “forecasting”).
Pour aller au-delà du machine learning : le deep learning et les réseaux de neurones profonds
Le machine learning regroupe des algorithmes de complexité simple à moyenne. Mais certaines tâches comme la reconnaissance d’objets dans des images ou l’analyse de textes nécessitent de concevoir des modèles plus complexes, des modèles profonds.
- Deep learning : apprentissage profond. Il s’agit d’une forme d’apprentissage automatique mobilisant des réseaux de neurones profonds. La combinaison de plusieurs couches permet au modèle d’apprendre des relations complexes entre ses données d’entrée : c’est de là que vient cette idée de profondeur. Les LLM font partie de cette catégorie, il s’agit de modèles profonds particulièrement grands.
- Paramètre : pour pouvoir apprendre, les modèles doivent avoir des paramètres, qui sont simplement des nombres, une forme de configuration définissant leur fonctionnement. L’apprentissage va faire évoluer ces paramètres pour leur permettre de calculer le résultat attendu selon l’entrée. Par exemple, un modèle peut apprendre que la température extérieure multipliée par 3.1415 prédit bien le nombre de glaces à la fraise vendues en une heure. Les neurones d’un modèle profond sont des paramètres, et en posséder beaucoup permet d’apprendre à réaliser des tâches complexes.
 Les réseaux de neurones profonds peuvent être entraînés à reconnaître des objets dans des images.
Les réseaux de neurones profonds peuvent être entraînés à reconnaître des objets dans des images.
Les LLM : des réseaux de neurones profonds vraiment très grands et capables de tenir une conversation
Nous pouvons désormais définir les LLM, et le domaine dans lequel il s’inscrivent, l’analyse de textes.
- LLM : un “Large Language Model” ou grand modèle de langage est un modèle profond de très grande taille spécialisé dans l’analyse de texte. Il s’avère qu’au-delà d’un certain nombre de paramètres ou de “neurones”, les modèles profonds développent des capacités de généralisation très puissantes. Les LLM peuvent accomplir plusieurs tâches, par exemple détecter si un texte évoque un sentiment positif ou négatif, le traduire, le synthétiser, et bien sûr générer des textes. Alors que jusqu’à présent, il était généralement nécessaire de créer un nouveau modèle pour chaque tâche à résoudre, et générer des textes complexes à la demande était quasiment impossible.
Au pluriel, LLM ou LLMs? En français, un acronyme en majuscule n’est pas censé prendre de “s” final, donc “LLM” est le pluriel correct. Cependant, il s’agit d’un acronyme anglais, il n’est donc pas étonnant de lire “des LLMs” voire des “LLM’s”. On n’est plus à un anglicisme près en informatique !
- Language naturel : un texte écrit par un humain, par opposition à un programme informatique ou une donnée structurée par exemple. On peut communiquer avec un LLM en langage naturel, et il répond alors aussi en langage naturel.
- Natural Language Processing : le NLP ou en français “Traitement Automatique du Langage (TAL)” est la discipline consistant à analyser des textes automatiquement, en particulier avec des algorithmes de machine learning, de deep learning et donc désormais des LLM.
- GPT : “Generative Pre-trained”, il s’agit d’un type de LLM spécifique proposé par la société OpenAI. Parler d’un “GPT” ou “ChatGPT” au lieu de LLM est donc un abus de langage, sauf si vous utilisez littéralement les solutions d’Open AI.
 Mistral ne semble pas être un grand amateur de glace.
Mistral ne semble pas être un grand amateur de glace.
Dompter un LLM… ou plutôt prompter un LLM
On peut discuter avec un LLM, et lui demander d’accomplir des tâches complexes, sans être développeur informatique. C’est ce qui fait leur popularité ! Néanmoins, il faut connaître quelques termes pour comprendre comment bien utiliser un LLM.
- Token : un LLM raisonne en terme de tokens plutôt que de “mots”. Il peut s’agir de mots entiers, de morceaux de mots, de séparateurs pour différencier les instructions de l’humain et la réponse du LLM par exemple. La facturation de l’utilisation d’un LLM se fait souvent en fonction du nombre de tokens fournis en entrée ou générés par le modèle en réponse aux questions de l’utilisateur.
- Prompt : il s’agit de l’instruction fournie au LLM pour qu’il accomplisse une tâche. Les grands modèles de langage sont en général spécialement entraînés pour répondre à des instructions fournies par des humains, en langage naturel. On peut leur demander de classer un texte dans une catégorie, de le traduire, le synthétiser… Alors que les modèles de NLP étaient jusqu’à présent généralement spécialisés pour une seule tâche spécifique.
- Prompt engineering : on ne peut pas vraiment prédire à l’avance quel prompt sera le plus efficace pour pousser le LLM à accomplir une tâche, car il s’agit de modèles excessivement complexes, dont le comportement est difficile à expliquer et à prédire. Le prompt engineering est donc l’art de rédiger des prompts efficaces. On peut prouver scientifiquement que certains prompts sont meilleures que d’autres, mais le mieux est de faire des essais soi-même selon le problème que l’on veut résoudre.
- Contexte ou fenêtre de contexte : il s’agit de la taille maximale d’un prompt, qui est grande avec les modèles récents mais pas infinie. Traiter des documents très longs demande de mettre en œuvre des techniques particulières, comme l’architecture RAG.
IA générative : pour le texte, les images, les vidéos et bien d’autres encore
Les LLM sont donc spécifiques au domaine du texte. Mais il existe aussi des grands modèles pour le traitement des images, la génération de vidéo, de données structurées… Voici quelques définitions plus générales qui s’appliquent à tous les domaines.
- IA générative : les LLM sont entraînés à prédire le mot suivant d’une phrase, ils peuvent donc générer des textes en réponse à un prompt. L’IA générative désigne plus généralement tous les modèles apprenants capables de générer des contenus à partir d’une instruction. Les modèles de diffusion peuvent par exemple générer une image à partir d’un texte.
- Modèle de fondation : un modèle de fondation est un modèle généraliste, que l’on peut utiliser pour plusieurs tâches. Les LLM sont des modèles de fondation pour le traitement du langage naturel, mais on peut aussi concevoir des modèles de fondation pour le traitement d’images, de vidéos, ou d’autres typologies de données. Cette notion s’oppose aux modèles qui existaient jusqu’à présent et qui avaient tendance à être spécialisés pour réaliser une tâche précise : recommander des produits sur le site d’un e-commerçant, détecter une anomalie dans un système informatique, classer des photographies d’animaux par espèce…
- Transformers : il s’agit de l’architecture de réseaux de neurones profonds qui rend possible les LLM, car elle fonctionne très bien pour des réseaux très grands et des séquences d’entrée (donc des textes) très longs. Elle a été conçue par Google et présentée en 2017.
- Multi-modalité : les modèles de fondation peuvent accomplir plusieurs tâches, mais seulement pour un type de donnée : des textes pour les LLM, des images pour les modèles de diffusion. La multimodalité vise à casser ces silos, en permettant à un modèle de traiter des documents contenant à la fois des images et du texte par exemple.
 Une image de glace générée par une IA générative. Pas mauvais.
Une image de glace générée par une IA générative. Pas mauvais.
Les techniques avancées
Voilà, on en sait désormais plus sur les LLM ! Cependant, ce n’est pas fini, car il s’avère qu’on peut réaliser des tâches encore plus avancées si l’on intègre un LLM à un programme informatique complexe. C’est pourquoi LBKE offre des formations pour devenir développeur LLM avec Python (LangChain) ou développeur LLM avec JavaScript.
La suite de ce lexique vous permettra de comprendre les concepts abordés durant ces formations.
- Embeddings : “plongement de mot” en bon français, ou vecteurs sémantiques, il s’agit concrètement de tableaux de nombre qui font tous la même taille et qui représente un mot, une phrase, voire un document. Les LLM produisent naturellement des embeddings pour représenter les textes qui leurs sont donnés en entrée, ce format est nécessaire pour qu’ils puissent raisonner en termes mathématiques à partir d’un texte. Lorsque l’on parle d’espace latent ou d’apprentissage de représentation, cela est lié au calcul des embeddings.
- Recherche sémantique : en traduisant une requête d’un moteur de recherche en plongements, on peut trouver des résultats en tenant compte des synonymes, ce qui était auparavant un problème difficile. En effet deux mots qui ont tendances à être utilisés dans les mêmes phrases vont avoir tendance à avoir des embeddings proches, au sens mathématique du terme. Par exemple “adopter un chat” aura un plongement proche de “refuge SPA le plus proche”, alors qu’aucun des mots ne sont identiques ! C’est très utile pour créer des moteurs de recherche.
- RAG : “Retriveal-Assisted Generation”, il s’agit de coupler un moteur de recherche sémantique et un LLM. En plus de la requête de l’utilisateur, on fournit au LLM les résultats d’une recherche sémantique. Lorsque l’on demande à un LLM de générer un programme informatique, cela permet par exemple de récupérer la documentation la plus à jour pour une librairie de code. Le résultat sera de meilleure qualité.
- Hallucinations : les LLM ont tendance à inventer les réponses qu’ils ne connaissent pas. Les RAG permettent de limiter ce problème, car on fournit au LLM des informations fiables pour qu’il génère une réponse de qualité.
- Agent : on peut apprendre à un LLM à utiliser des outils, par exemple lancer des recherches sur le web ou stocker des informations dans une base de données. On peut aussi créer des programmes informatiques complexes qui combinent plusieurs appels de LLM. On parle alors d’agent, un programme intelligent et autonome fondé sur un LLM. Les agents peuvent accomplir des tâches difficiles comme naviguer en autonomie sur Internet. Cependant leur dépendance à de multiples appels à des LLM peut les rendre relativement lents.
- MLOps, LLMOps : c’est l’application du paradigme DevOps aux algorithmes de machine learning et plus particulièrement aux LLM. Les LLM sont coûteux à entraîner et à utiliser, en puissance de calcul, en temps, en énergie : gérer les infrastructures informatiques sous-jacentes est une discipline en soi, que l’on commence à appeler LLMOps. C’est un métier d’avenir !
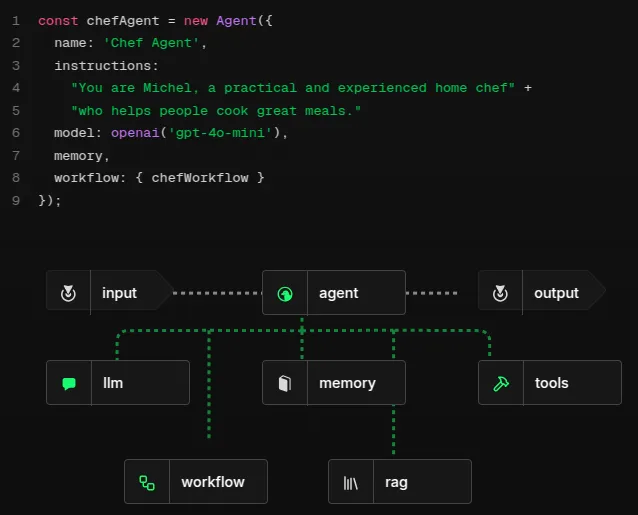
Chef Michel, un agent conversationnel (chatbot) autonome pour aider à cuisiner des plats, créé avec le framework TypeScript Mastra.ai. Chef Michel utilise plusieurs approches pour obtenir de bons résultats : mémoriser ses conversations précédentes avec l’utilisateur, chercher des informations à jour dans une base de données… Le LLM est son cerveau !
Merci pour votre lecture !
Voilà, nous avons fait le tour des termes les plus utiles pour comprendre les LLM ! Si vous voulez passer à la pratique, prenez le temps de lire notre programme de formation à l’IA en entreprise. On y aborde le principe de l’IA avec du temps pour la mise en pratique et le prompt engineering, mais aussi les aspects organisationnels, éthiques et légaux que les managers techniques doivent maîtriser pour mettre en oeuvre l’IA générative dans leurs entreprises.
Pour continuer à découvrir les LLM
Si avez de nouveaux besoin de trouver des définitions de qualité, voici plusieurs sources qui peuvent être pertinentes. Les grands acteurs de l’informatique, de l’hébergement cloud fournissent généralement de bonnes définitions pour les termes de l’IA. Il est aussi intéressant de découvrir les définitions adoptées par des instances officielles comme le parlement européen.
Quelques exemples :
